在过去一段时间内,有一套相同的软件在不同的部署环境之间,断断续续有现场反馈出现 Pod 在用域名访问 Service 的时候无法解析域名。经过简单排查:
- 排除掉了使用姿势问题,即
pod.spec.dnsPolicy是正确配置的; - 排除了运行时问题,即 Pod 里
/etc/resolv.conf是符合预期的; - 排除了网络问题,即 Pod 来回到 CoreDNS 的 UDP/TCP 都是正常通信无丢包的;
那么,排除掉基础设施的问题,去怀疑的用户态应用层就很合理了。而且众所周知且 Musl 被广为诟病(虽然其实可能是 Glibc 实现不规范的问题)的是 Musl 在容器里一直多多少少存在些坑,这点在差不多 10 年前就已经领教了过了因为 musl 不认识 nsswitch.conf 导致 Go 程序出问题。
排查中得知,的确出问题的 Pod 都是使用的 Alpine,所以基本上可以确定是 Musl 的问题,但是还有一个关键问题没有搞清楚:
为什么有的环境是好的,有的环境就不行了。这究竟是命中了什么 Musl 的哪个场景导致了这个行为?
这不是巧了么,这个问题属于三不管:
- 系统团队:管我屁事,你又没用我们的发行版本;
- DNS 团队:我看 DNS 都是好的,你看宿主机上就返回的很快,是网络问题吧?是 K8s 问题吧?
- 业务团队:我测过都是好的,你说的我听不懂,阿巴阿巴。但是我换镜像、测试、发 hotfix 要 N 天,肯定都是 K8s 的问题。
- 现场运维:客户说了,不管你用啥方法,这周要找到原因修好。另外,你先告诉我一个绕过的方法。
屮,行吧。
TLDR
musl 遇到 SERVFAIL 响应会直接终止查询,而 glibc 不会。因此在某些特殊配置的 DNS 服务器上,可能会导致能在 glibc 上正确解析的域名在 musl 中无法解析。而对于CoreDNS 而言,如果一个域不知道如何处理的时候,比如没有被 forward、proxy、file 等插件接住处理的时候,就会返回 SERVFAIL。
调查过程
先梳理下环境以及线索,Pod 内的 /etc/resolv.conf 看起来如下。其中 something-else.com 是集成于宿主机的内容,其他都是 kubelet 注入的:
1 | search default.svc.cluster.local svc.cluster.local cluster.local something-else.com |
使用场景方面:
- Pod 使用 FQDN 域名 (如
<svc-name>.<ns>.svc.cluster.local这样完整的域名) 访问 Service,相同的 FQDN 域名在宿主机上正确返回,在 Pod 内超时失败; - 出现问题的 Pod 有容器网络的,也有 Host 网络的。但不管是哪个模式
/etc/resolv.conf都正确配置指向了 CoreDNS,并且搜索域等参数符合预期,没人改过; - 现场尝试魔改
/etc/resolv.conf里的ndots参数,把默认的ndots:5改成ndots:4之后通了。
由于修改成为 ndots:4 后能正确解析,而且 K8s Service 的 FQDN 肯定都是四个点的,所以 /etc/resolv.conf 内的搜索域就应该完全跳过,域名按照 Global Domain 来进行解析的时候,域名是能正确解析并返回的。这是符合预期的,因为现在解析的域名已经是 Service 的 FQDN 了,所以本来就预期在全局域内被解析。但是,奇怪就奇怪在了如果在 /etc/resolv.conf 内的搜索域查询过之后,这个 FQDN 的查询就不工作了。
这中间一定发生了什么奇怪的事情,在容器内使用 ping 域名的方式让 musl 来解析域名,配合 strace 和 tcpdump 进行行为观察。图不方便发出来,但是结论就是 musl 在所有搜索域尝试完毕并失败后,并没有尝试在全局域内发起查询。
在开发环境构建相似场景,在 /etc/resolv.conf 内添加 options ndots:5 后,并添加了两个不存在的搜索域 search1 和 search2,发起查询 baidu.com 并抓包结如下,此时可见 musl 在各搜索域内失败后,是会在全局域下发起查询的。
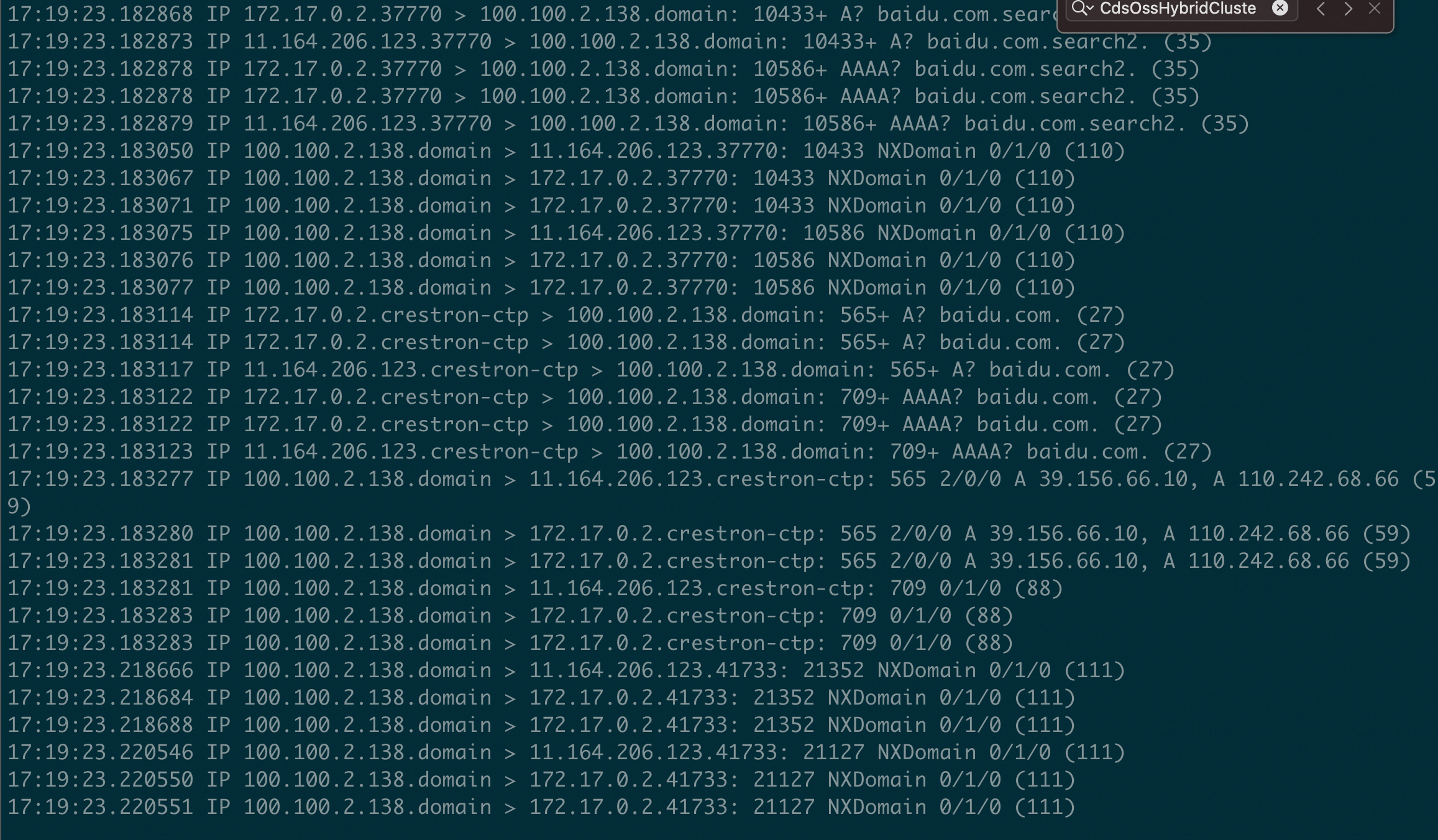
那么这个就非常奇怪了,看看代码是否存在线索。在容器里 apk list 查到环境里的 musl 版本是 1.1.24,下载对应版本代码读一下:
1 | static int name_from_dns_search(struct address buf[static MAXADDRS], char canon[static 256], const char *name, int family) |
从代码可知,本来预期每个搜索域查询失败后,在最后发起一个全局域内的查询。如果跳过的话,只有可能在前面的查询返回的 cnt 非 0,而 name_from_dns 内,只要发生了任何异常都会返回,无论是网络错误还是查询结果不符合预期。
1 | static int name_from_dns(struct address buf[static MAXADDRS], char canon[static 256], const char *name, int family, const struct resolvconf *conf) |
因为网络上是通的且在宿主机上能正常响应,那么说明应该是响应中的某个地方不预期,继而导致的返回。为了查看区别,我们使用 dig 在宿主机上主动在各搜索域内进行查询。即如果以 default namesapce 下的 mysql service 为例,尝试逐个查询:
mysql.default.svc.cluster.local.default.svc.cluster.localmysql.default.svc.cluster.local.svc.cluster.localmysql.default.svc.cluster.local.cluster.localmysql.default.svc.cluster.local.something-else.commysql.default.svc.cluster.local
尝试到 3 和 4 的时候,出现了一些些不一样的地方:前者返回 NXDOMAIN 而后者返回 SERVFAIL。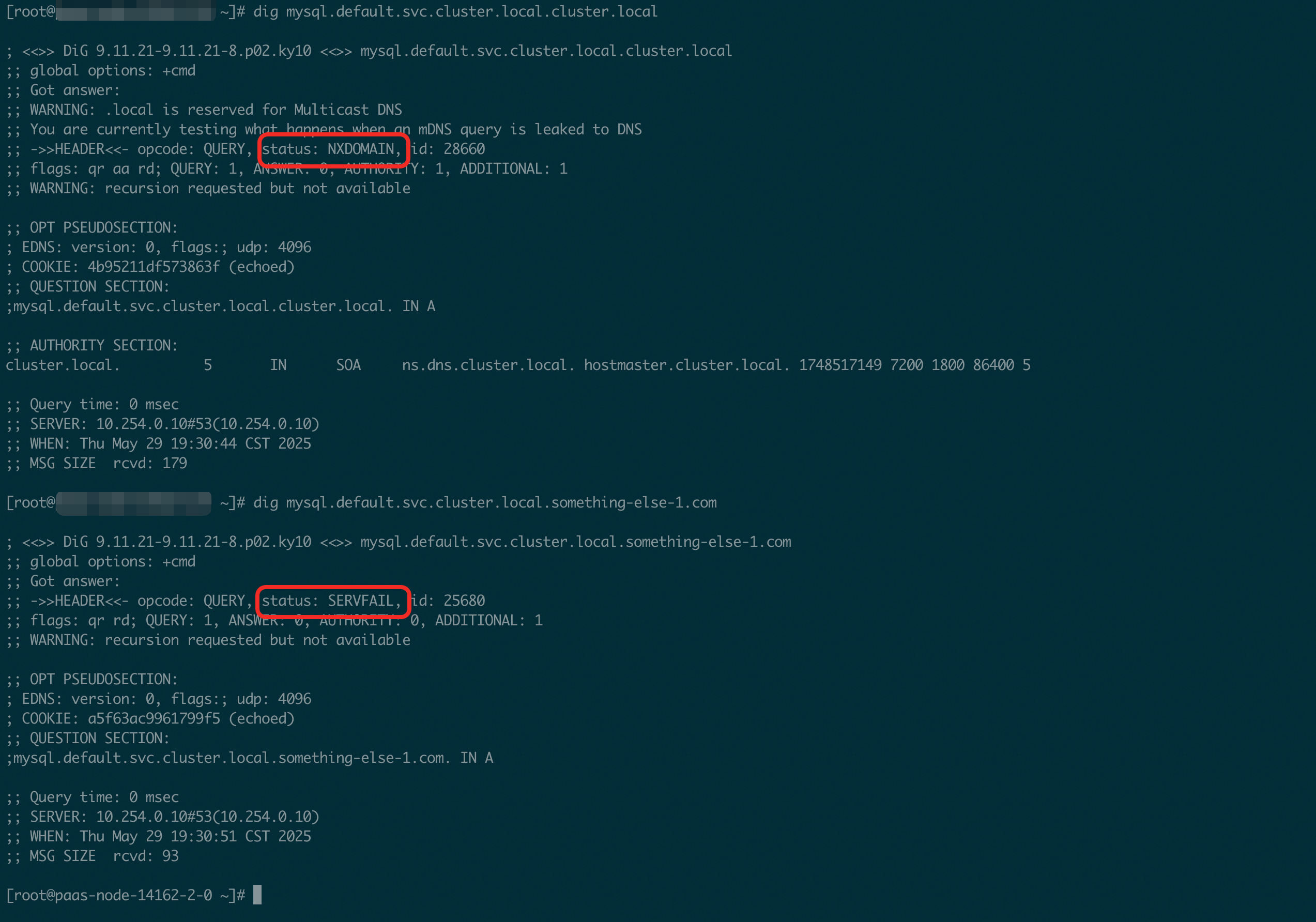
检查 CoreDNS 的配置,可见 Corefile 中并没有配置 forward 参数。至于原因嘛,是因为这个环境中就没有可用的 DNS 服务器,而所有宿主机 /etc/resolv.conf 中指向的就是这个 CoreDNS,所以常见的 forward 自然就不能有了,否则就会循环了。
1 | .:53 { |
由于没有 forward,在尝试向最后一个搜索域 something-else.com 搜索的时候也没有在 file 插件的数据库中找到,无法处理当前请求的情况下返回了一个SERVFAIL。而 musl 在 SERVFAIL 的处理逻辑与 glibc 不同:musl 会直接终止查询而 glibc 不会。这点在 musl 的 FAQ 中没有详细提及,但是在 2018 年在邮件列表中 musl 的维护者对此有过解释:Re: [PATCH] resolver: only exit the search path loop there are a positive number of results given
作者认为面对 SERVFAIL 这种服务器错误应该立刻停止查询以避免不可预知的行为,而不是当作 NXDOMAIN 无记录的正常响应来继续处理。就好比 RESTful API 返回 500 的时候,客户端不应该把它当作 200 的空列表继续处理一样。但是事实上,这个点上我并没有找到 RFC 文档明文规定必须这么做,只是从返回码的语义上进行了体现。另外,对于 glibc 这样广泛使用的库而言,已经成为了事实标准。glibc 的这种行为上模棱两可的 bug 已经是 feature 了,人们管它叫 怪癖(quirks)。
那么这个时候就可以回答一开始的问题了:为什么有的环境是好的,有的环境是坏的?原因有两种可能:
- 有的环境有默认 DNS 服务器,未知的域会被转发到上游进行递归查询;
- 有的环境部署的时候,开出来的机器上没有这种莫名其妙的搜索域,所以不会触发问题;
行吧。既然问题找到了,那谁该修谁修总跑不掉了吧?我下班了。